Kryo 和 FST 序列化
此文档已经不再维护。您当前查看的是快照版本。如果想要查看最新版本的文档,请参阅最新版本。
目录
- 序列化漫谈
- 启用Kryo和FST
- 注册被序列化类
- 无参构造函数和Serializable接口
- 序列化性能分析与测试
- 测试环境
- 测试脚本
- Dubbo RPC中不同序列化生成字节大小比较
- Dubbo RPC中不同序列化响应时间和吞吐量对比
- 未来
序列化漫谈
dubbo RPC是dubbo体系中最核心的一种高性能、高吞吐量的远程调用方式,我喜欢称之为多路复用的TCP长连接调用,简单的说:
- 长连接:避免了每次调用新建TCP连接,提高了调用的响应速度
- 多路复用:单个TCP连接可交替传输多个请求和响应的消息,降低了连接的等待闲置时间,从而减少了同样并发数下的网络连接数,提高了系统吞吐量。
dubbo RPC主要用于两个dubbo系统之间作远程调用,特别适合高并发、小数据的互联网场景。
而序列化对于远程调用的响应速度、吞吐量、网络带宽消耗等同样也起着至关重要的作用,是我们提升分布式系统性能的最关键因素之一。
在dubbo RPC中,同时支持多种序列化方式,例如:
- dubbo序列化:阿里尚未开发成熟的高效java序列化实现,阿里不建议在生产环境使用它
- hessian2序列化:hessian是一种跨语言的高效二进制序列化方式。但这里实际不是原生的hessian2序列化,而是阿里修改过的hessian lite,它是dubbo RPC默认启用的序列化方式
- json序列化:目前有两种实现,一种是采用的阿里的fastjson库,另一种是采用dubbo中自己实现的简单json库,但其实现都不是特别成熟,而且json这种文本序列化性能一般不如上面两种二进制序列化。
- java序列化:主要是采用JDK自带的Java序列化实现,性能很不理想。
在通常情况下,这四种主要序列化方式的性能从上到下依次递减。对于dubbo RPC这种追求高性能的远程调用方式来说,实际上只有1、2两种高效序列化方式比较般配,而第1个dubbo序列化由于还不成熟,所以实际只剩下2可用,所以dubbo RPC默认采用hessian2序列化。
但hessian是一个比较老的序列化实现了,而且它是跨语言的,所以不是单独针对java进行优化的。而dubbo RPC实际上完全是一种Java to Java的远程调用,其实没有必要采用跨语言的序列化方式(当然肯定也不排斥跨语言的序列化)。
最近几年,各种新的高效序列化方式层出不穷,不断刷新序列化性能的上限,最典型的包括:
- 专门针对Java语言的:Kryo,FST等等
- 跨语言的:Protostuff,ProtoBuf,Thrift,Avro,MsgPack等等
这些序列化方式的性能多数都显著优于hessian2(甚至包括尚未成熟的dubbo序列化)。
有鉴于此,我们为dubbo引入Kryo和FST这两种高效Java序列化实现,来逐步取代hessian2。
其中,Kryo是一种非常成熟的序列化实现,已经在Twitter、Groupon、Yahoo以及多个著名开源项目(如Hive、Storm)中广泛的使用。而FST是一种较新的序列化实现,目前还缺乏足够多的成熟使用案例,但我认为它还是非常有前途的。
在面向生产环境的应用中,我建议目前更优先选择Kryo。
启用Kryo和FST
使用Kryo和FST非常简单,只需要在dubbo RPC的XML配置中添加一个属性即可:
<dubbo:protocol name="dubbo" serialization="kryo"/>
<dubbo:protocol name="dubbo" serialization="fst"/>
注册被序列化类
要让Kryo和FST完全发挥出高性能,最好将那些需要被序列化的类注册到dubbo系统中,例如,我们可以实现如下回调接口:
public class SerializationOptimizerImpl implements SerializationOptimizer {
public Collection<Class> getSerializableClasses() {
List<Class> classes = new LinkedList<Class>();
classes.add(BidRequest.class);
classes.add(BidResponse.class);
classes.add(Device.class);
classes.add(Geo.class);
classes.add(Impression.class);
classes.add(SeatBid.class);
return classes;
}
}
然后在XML配置中添加:
<dubbo:protocol name="dubbo" serialization="kryo" optimizer="org.apache.dubbo.demo.SerializationOptimizerImpl"/>
在注册这些类后,序列化的性能可能被大大提升,特别针对小数量的嵌套对象的时候。
当然,在对一个类做序列化的时候,可能还级联引用到很多类,比如Java集合类。针对这种情况,我们已经自动将JDK中的常用类进行了注册,所以你不需要重复注册它们(当然你重复注册了也没有任何影响),包括:
GregorianCalendar
InvocationHandler
BigDecimal
BigInteger
Pattern
BitSet
URI
UUID
HashMap
ArrayList
LinkedList
HashSet
TreeSet
Hashtable
Date
Calendar
ConcurrentHashMap
SimpleDateFormat
Vector
BitSet
StringBuffer
StringBuilder
Object
Object[]
String[]
byte[]
char[]
int[]
float[]
double[]
由于注册被序列化的类仅仅是出于性能优化的目的,所以即使你忘记注册某些类也没有关系。事实上,即使不注册任何类,Kryo和FST的性能依然普遍优于hessian和dubbo序列化。
当然,有人可能会问为什么不用配置文件来注册这些类?这是因为要注册的类往往数量较多,导致配置文件冗长;而且在没有好的IDE支持的情况下,配置文件的编写和重构都比java类麻烦得多;最后,这些注册的类一般是不需要在项目编译打包后还需要做动态修改的。
另外,有人也会觉得手工注册被序列化的类是一种相对繁琐的工作,是不是可以用annotation来标注,然后系统来自动发现并注册。但这里annotation的局限是,它只能用来标注你可以修改的类,而很多序列化中引用的类很可能是你没法做修改的(比如第三方库或者JDK系统类或者其他项目的类)。另外,添加annotation毕竟稍微的“污染”了一下代码,使应用代码对框架增加了一点点的依赖性。
除了annotation,我们还可以考虑用其它方式来自动注册被序列化的类,例如扫描类路径,自动发现实现Serializable接口(甚至包括Externalizable)的类并将它们注册。当然,我们知道类路径上能找到Serializable类可能是非常多的,所以也可以考虑用package前缀之类来一定程度限定扫描范围。
当然,在自动注册机制中,特别需要考虑如何保证服务提供端和消费端都以同样的顺序(或者ID)来注册类,避免错位,毕竟两端可被发现然后注册的类的数量可能都是不一样的。
无参构造函数和Serializable接口
如果被序列化的类中不包含无参的构造函数,则在Kryo的序列化中,性能将会大打折扣,因为此时我们在底层将用Java的序列化来透明的取代Kryo序列化。所以,尽可能为每一个被序列化的类添加无参构造函数是一种最佳实践(当然一个java类如果不自定义构造函数,默认就有无参构造函数)。
另外,Kryo和FST本来都不需要被序列化的类实现Serializable接口,但我们还是建议每个被序列化类都去实现它,因为这样可以保持和Java序列化以及dubbo序列化的兼容性,另外也使我们未来采用上述某些自动注册机制带来可能。
序列化性能分析与测试
本文我们主要讨论的是序列化,但在做性能分析和测试的时候我们并不单独处理每种序列化方式,而是把它们放到dubbo RPC中加以对比,因为这样更有现实意义。
测试环境
粗略如下:
- 两台独立服务器
- 4核Intel(R) Xeon(R) CPU E5-2603 0 @ 1.80GHz
- 8G内存
- 虚拟机之间网络通过百兆交换机
- CentOS 5
- JDK 7
- Tomcat 7
- JVM参数-server -Xms1g -Xmx1g -XX:PermSize=64M -XX:+UseConcMarkSweepGC
当然这个测试环境较有局限,故当前测试结果未必有非常权威的代表性。
测试脚本
和dubbo自身的基准测试保持接近:
10个并发客户端持续不断发出请求:
- 传入嵌套复杂对象(但单个数据量很小),不做任何处理,原样返回
- 传入50K字符串,不做任何处理,原样返回(TODO:结果尚未列出)
进行5分钟性能测试。(引用dubbo自身测试的考虑:“主要考察序列化和网络IO的性能,因此服务端无任何业务逻辑。取10并发是考虑到rpc协议在高并发下对CPU的使用率较高可能会先打到瓶颈。”)
Dubbo RPC中不同序列化生成字节大小比较
序列化生成字节数的大小是一个比较有确定性的指标,它决定了远程调用的网络传输时间和带宽占用。
针对复杂对象的结果如下(数值越小越好):
| 序列化实现 | 请求字节数 | 响应字节数 |
|---|---|---|
| Kryo | 272 | 90 |
| FST | 288 | 96 |
| Dubbo Serialization | 430 | 186 |
| Hessian | 546 | 329 |
| FastJson | 461 | 218 |
| Json | 657 | 409 |
| Java Serialization | 963 | 630 |
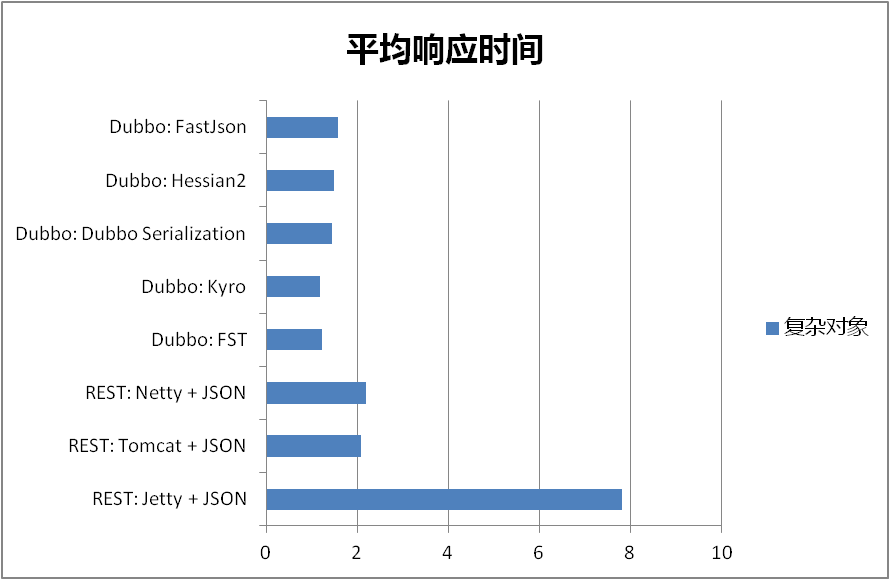
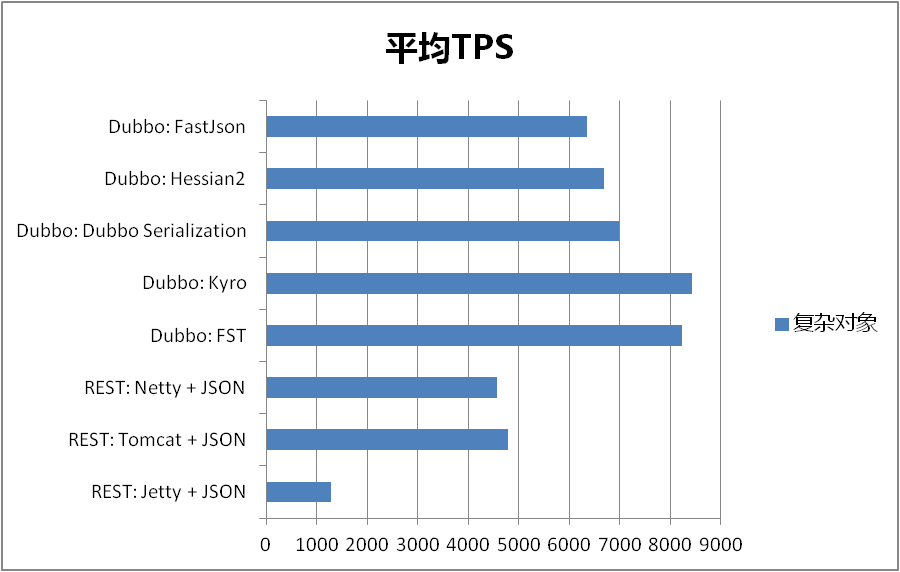
Dubbo RPC中不同序列化响应时间和吞吐量对比
| 远程调用方式 | 平均响应时间 | 平均TPS(每秒事务数) |
|---|---|---|
| REST: Jetty + JSON | 7.806 | 1280 |
| REST: Jetty + JSON + GZIP | TODO | TODO |
| REST: Jetty + XML | TODO | TODO |
| REST: Jetty + XML + GZIP | TODO | TODO |
| REST: Tomcat + JSON | 2.082 | 4796 |
| REST: Netty + JSON | 2.182 | 4576 |
| Dubbo: FST | 1.211 | 8244 |
| Dubbo: kyro | 1.182 | 8444 |
| Dubbo: dubbo serialization | 1.43 | 6982 |
| Dubbo: hessian2 | 1.49 | 6701 |
| Dubbo: fastjson | 1.572 | 6352 |
测试总结
就目前结果而言,我们可以看到不管从生成字节的大小,还是平均响应时间和平均TPS,Kryo和FST相比Dubbo RPC中原有的序列化方式都有非常显著的改进。
未来
未来,当Kryo或者FST在dubbo中当应用足够成熟之后,我们很可能会将dubbo RPC的默认序列化从hessian2改为它们中间的某一个。