该文章内容发布已经超过一年,请注意检查文章中内容是否过时。
Dubbo 一致性Hash负载均衡实现剖析
需要强调的是,Dubbo的Hash映射模型与大部分网上资料描述的环形队列Hash映射模型是存在一些区别的。于我而言,环形队列Hash映射模型,不足以让我对一致性Hash有足够彻底的了解。直到看懂了Dubbo的一致性Hash的实现,才觉得豁然开朗。
一、环形队列Hash映射模型
这种方案,其基础还是基于取模运算。对2^32取模,那么,Hash值的区间为[0, 2^32-1]。接下来要做的,就包括两部分:
a、映射服务
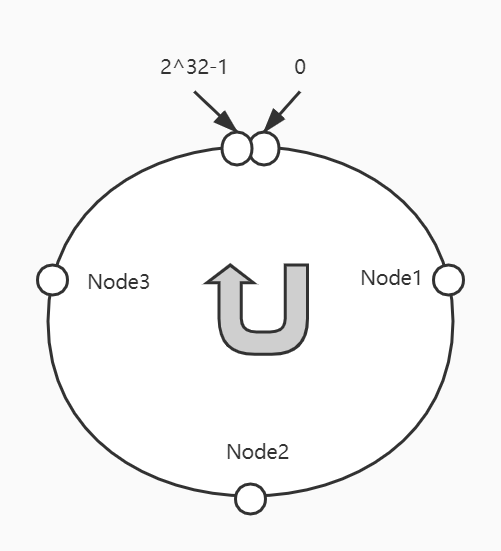
将服务地址(ip+端口)按照一定规则构造出特定的识别码(如md5码),再用识别码对2^32取模,确定服务在Hash值区间对应的位置。假设有Node1、Node2、Node3三个服务,其映射关系如下:
b、映射请求、定位服务
在发起请求时,我们往往会带上参数,而这些参数,就可以被我们用来确定具体调用哪一个服务。假设有请求R1、R2、R3,对它们的参数也经过计算特定识别码、取余的一系列运算之后,有如下映射关系:
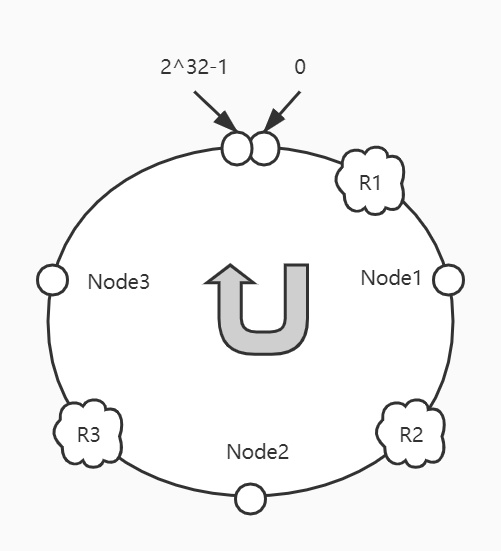
从图中,我们可以看到,R1请求映射在0-Node1中间,R2请求映射在Node1-Node2中间,R3请求映射在Node2-Node3中间。我们取服务Hash值大于请求Hash值的第一个服务作为实际的调用服务。也就是说,R1请求将调用Node1服务,R2请求将调用Node2服务,R3请求将调用Node3服务。
c、新增服务节点
假设新增服务Node4,映射在Node3之前,恰巧破坏了原来的一个映射关系:
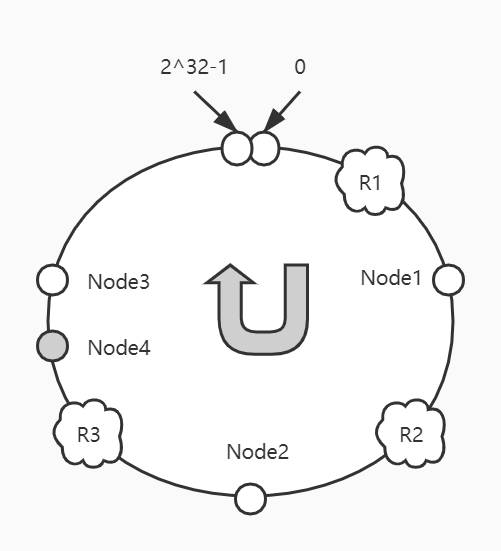
这样,请求R3将会实际调用服务Node4,但请求R1、R2不受影响。
d、删除服务节点
假设服务Node2宕机,那么R2请求将会映射到Node3:
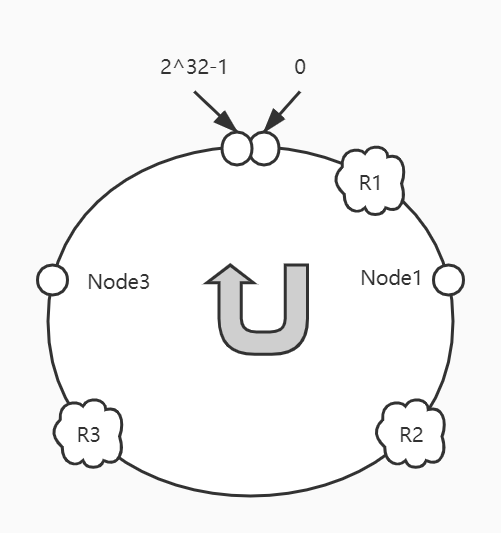
原本的R1、R3请求不受影响。
可以看出,当新增、删除服务时,受影响的请求是有限的。不至于像简单取模映射一般,服务发生变化时,需要调整全局的映射关系。
e、平衡性与虚拟节点
在我们上面的假设中,我们假设Node1、Node2、Node3三个服务在经过Hash映射后所分布的位置恰巧把环切成了均等的三分,请求的分布也基本是平衡的。但是实际上计算服务Hash值的时候,是很难这么巧的。也许一不小心就映射成了这个样子:
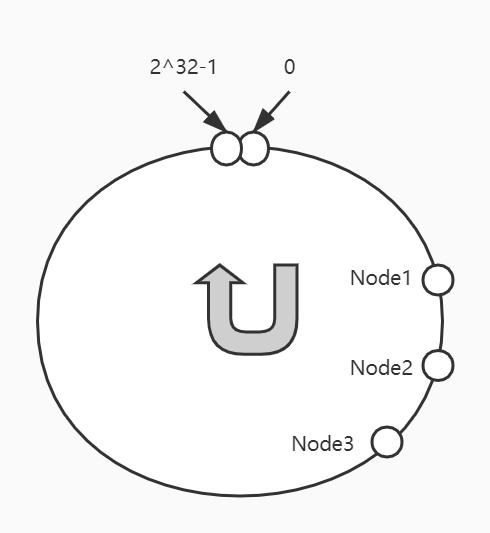
这样,就会导致大部分请求都会被映射到Node1上。因此,引出了虚拟节点。
所谓虚拟节点,就是除了对服务本身地址进行Hash映射外,还通过在它地址上做些处理(比如Dubbo中,在ip+port的字符串后加上计数符1、2、3……,分别代表虚拟节点1、2、3),以达到同一服务映射多个节点的目的。通过引入虚拟节点,我们可以把上图中映射给Node1的请求进一步拆分:
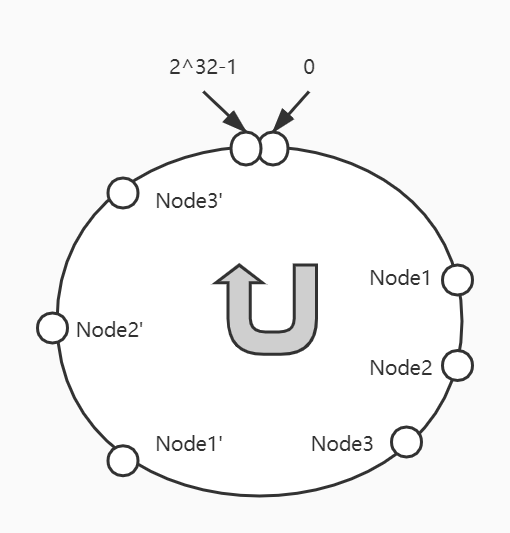
如上图所示,若有请求落在Node3-Node1’区间,该请求应该是调用Node1’服务,但是因为Node1’是Node1的虚拟节点,所以实际调用的是Node1服务。通过引入虚拟节点,请求的分布就会比较平衡了。
二、Dubbo一致性Hash的使用与负载均衡策略的引入阶段
a、如何使用一致性Hash作为Dubbo的负载均衡策略?
dubbo:service、dubbo:reference、dubbo:provider、dubbo:consumer、dubbo:method这几个配置项都可以配置Dubbo的负载均衡策略,其中一致性Hash的属性值是:consistenthash。
以dubbo:reference为例:
XML配置:
<dubbo:reference loadbalance=“consistenthash” />
Properties配置:
dubbo.reference.loadbalance=consistenthash
注解:
@Reference(loadbalance = “consistenthash”)
b、Dubbo负载均衡策略的引入阶段
Dubbo实现的是客户端负载均衡。关于服务接口代理类的实现,这里不做详细描述,可以参考官网:
服务引入:/zh-cn/docs/source_code_guide/refer-service.html。
在接口代理类生成、并且装配好后,服务的调用基本是这样一个流程:proxy -> MockClusterInvoker -> 集群策略(如:FailoverClusterInvoker) -> 初始化负载均衡策略 -> 根据选定的负载均衡策略确定Invoker。
负载均衡策略的初始化是在AbstractClusterInvoker中的initLoadBalance方法中初始化的:
protected LoadBalance initLoadBalance(List<Invoker<T>> invokers, Invocation invocation) {
if (CollectionUtils.isNotEmpty(invokers)) {
return ExtensionLoader.getExtensionLoader(LoadBalance.class).getExtension(invokers.get(0).getUrl()
.getMethodParameter(RpcUtils.getMethodName(invocation), LOADBALANCE_KEY, DEFAULT_LOADBALANCE));
} else {
return ExtensionLoader.getExtensionLoader(LoadBalance.class).getExtension(DEFAULT_LOADBALANCE);
}
}
这部分代码逻辑分为两部分:
1、获取调用方法所配置的LOADBALANCE_KEY属性的值,LOADBALANCE_KEY这个常量的实际值为:loadbalance,即为我们的所配置的属性;
2、利用SPI机制来初始化并加载该值所代表的负载均衡策略。
所有的负载均衡策略都会继承LoadBalance接口。在各种集群策略中,最终都会调用AbstractClusterInvoker的select方法,而AbstractClusterInvoker会在doSelect中,调用LoadBalance的select方法,这里即开始了负载均衡策略的执行。
三、Dubbo一致性Hash负载均衡的实现
需要说明的一点是,我所说的负载均衡策略的执行,即是在所有的Provider中选出一个,作为当前Consumer的远程调用对象。在代码中,Provider被封装成了Invoker实体,所以直接说来,负载均衡策略的执行就是在Invoker列表中选出一个Invoker。
所以,对比普通一致性Hash的实现,Dubbo的一致性Hash算法也可以分为两步:
1、映射Provider至Hash值区间中(实际中映射的是Invoker);
2、映射请求,然后找到大于请求Hash值的第一个Invoker。
a、映射Invoker
Dubbo中所有的负载均衡实现类都继承了AbstractLoadBalance,调用LoadBalance的select方法时,实际上调用的是AbstractLoadBalance的实现:
@Override
public <T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) {
if (CollectionUtils.isEmpty(invokers)) {
return null;
}
if (invokers.size() == 1) {
return invokers.get(0);
}
// doSelect这里进入具体负载均衡算法的执行逻辑
return doSelect(invokers, url, invocation);
}
可以看到这里调用了doSelect,Dubbo一致性Hash的具体实现类名字是ConsistentHashLoadBalance,让我们来看看它的doSelect方法干了啥:
@Override
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
String methodName = RpcUtils.getMethodName(invocation);
// key格式:接口名.方法名
String key = invokers.get(0).getUrl().getServiceKey() + "." + methodName;
// identityHashCode 用来识别invokers是否发生过变更
int identityHashCode = System.identityHashCode(invokers);
ConsistentHashSelector<T> selector = (ConsistentHashSelector<T>) selectors.get(key);
if (selector == null || selector.identityHashCode != identityHashCode) {
// 若不存在"接口.方法名"对应的选择器,或是Invoker列表已经发生了变更,则初始化一个选择器
selectors.put(key, new ConsistentHashSelector<T>(invokers, methodName, identityHashCode));
selector = (ConsistentHashSelector<T>) selectors.get(key);
}
return selector.select(invocation);
}
这里有个很重要的概念:选择器——selector。这是Dubbo一致性Hash实现中,承载着整个映射关系的数据结构。它里面主要有这么几个参数:
/**
* 存储Hash值与节点映射关系的TreeMap
*/
private final TreeMap<Long, Invoker<T>> virtualInvokers;
/**
* 节点数目
*/
private final int replicaNumber;
/**
* 用来识别Invoker列表是否发生变更的Hash码
*/
private final int identityHashCode;
/**
* 请求中用来作Hash映射的参数的索引
*/
private final int[] argumentIndex;
在新建ConsistentHashSelector对象的时候,就会遍历所有Invoker对象,然后计算出其地址(ip+port)对应的md5码,并按照配置的节点数目replicaNumber的值来初始化服务节点和所有虚拟节点:
ConsistentHashSelector(List<Invoker<T>> invokers, String methodName, int identityHashCode) {
this.virtualInvokers = new TreeMap<Long, Invoker<T>>();
this.identityHashCode = identityHashCode;
URL url = invokers.get(0).getUrl();
// 获取配置的节点数目
this.replicaNumber = url.getMethodParameter(methodName, HASH_NODES, 160);
// 获取配置的用作Hash映射的参数的索引
String[] index = COMMA_SPLIT_PATTERN.split(url.getMethodParameter(methodName, HASH_ARGUMENTS, "0"));
argumentIndex = new int[index.length];
for (int i = 0; i < index.length; i++) {
argumentIndex[i] = Integer.parseInt(index[i]);
}
// 遍历所有Invoker对象
for (Invoker<T> invoker : invokers) {
// 获取Provider的ip+port
String address = invoker.getUrl().getAddress();
for (int i = 0; i < replicaNumber / 4; i++) {
byte[] digest = md5(address + i);
for (int h = 0; h < 4; h++) {
long m = hash(digest, h);
virtualInvokers.put(m, invoker);
}
}
}
}
这里值得注意的是:以replicaNumber取默认值160为例,假设当前遍历到的Invoker地址为127.0.0.1:20880,它会依次获得“127.0.0.1:208800”、“127.0.0.1:208801”、……、“127.0.0.1:2088040”的md5摘要,在每次获得摘要之后,还会对该摘要进行四次数位级别的散列。大致可以猜到其目的应该是为了加强散列效果。(希望有人能告诉我相关的理论依据。)
代码中 virtualInvokers.put(m, invoker) 即是存储当前计算出的Hash值与Invoker的映射关系。
这段代码简单说来,就是为每个Invoker都创建replicaNumber个节点,Hash值与Invoker的映射关系即象征着一个节点,这个关系存储在TreeMap中。
b、映射请求
让我们重新回到ConsistentHashLoadBalance的doSelect方法,若没有找到selector则会新建selector,找到selector后便会调用selector的select方法:
public Invoker<T> select(Invocation invocation) {
// 根据invocation的【参数值】来确定key,默认使用第一个参数来做hash计算
String key = toKey(invocation.getArguments());
// 获取【参数值】的md5编码
byte[] digest = md5(key);
return selectForKey(hash(digest, 0));
}
// 根据参数索引获取参数,并将所有参数拼接成字符串
private String toKey(Object[] args) {
StringBuilder buf = new StringBuilder();
for (int i : argumentIndex) {
if (i >= 0 && i < args.length) {
buf.append(args[i]);
}
}
return buf.toString();
}
// 根据参数字符串的md5编码找出Invoker
private Invoker<T> selectForKey(long hash) {
Map.Entry<Long, Invoker<T>> entry = virtualInvokers.ceilingEntry(hash);
if (entry == null) {
entry = virtualInvokers.firstEntry();
}
return entry.getValue();
}
argumentIndex是在初始化Selector的时候一起赋值的,代表着需要用哪几个请求参数作Hash映射获取Invoker。比如:有方法methodA(Integer a, Integer b, Integer c),如果argumentIndex的值为{0,2},那么即用a和c拼接的字符串来计算Hash值。
我们已经知道virtualInvokers是一个TreeMap,TreeMap的底层实现是红黑树。对于TreeMap的方法ceilingEntry(hash),它的作用是用来获取大于等于传入值的首个元素。可以看到,这一点与一般的一致性Hash算法的处理逻辑完全是相同的。
但这里的回环逻辑有点不同。对于取模运算来讲,大于最大值后,会自动回环从0开始,而这里的逻辑是:当没有比传入ceilingEntry()方法中的值大的元素的时候,virtualInvokers.ceilingEntry(hash)必然会得到null,于是,就用virtualInvokers.firstEntry()来获取整个TreeMap的第一个元素。
从selectForKey中获取到Invoker后,负载均衡策略也就算是执行完毕了。后续获取远程调用客户端等调用流程不再赘述。