Introduction to Dubbo
Apache Dubbo is an RPC service development framework, which is used to solve service governance and communication problems under the microservice architecture. It officially provides multi-language SDK implementations such as Java and Golang. Microservices developed using Dubbo are natively capable of remote address discovery and communication with each other. Using the rich service governance features provided by Dubbo, service governance demands such as service discovery, load balancing, and traffic scheduling can be realized. Dubbo is designed to be highly scalable, and users can easily implement various custom logics for traffic interception and location selection.
Dubbo3 is defined as a cloud-native-oriented next-generation RPC service framework. 3.0 has evolved based on Dubbo 2.x. While maintaining the original core features, Dubbo3 has improved in ease of use, ultra-large-scale microservice practice, cloud-native infrastructure adaptation, and security. Comprehensive upgrades have been made in several major directions, including ease of use, hyperscale microservice practices, cloud-native infrastructure adaptation, and security.
What is Dubbo
Apache Dubbo was originally donated by Alibaba as an open source in 2008, and soon became the de facto standard framework for the selection of open source service frameworks in China, and has been widely used in various industries. In 2017, Dubbo officially donated to the Apache Software Foundation and became a top-level project of Apache. Currently, Dubbo3 is already a one-stop microservice solution providing:
- HTTP/2-based Triple protocol and programming experience for proxy API.
- Powerful [traffic management capability] (../../tasks/traffic-management), such as address discovery, load balancing, routing address selection, dynamic configuration, etc.
- Multi-language SDK implementation, covering Java, Golang, Javascript, etc. More language implementations will be released in succession.
- Flexible adaptation and expansion capabilities, which can be easily adapted to other components of the microservice system such as Tracing and Transaction.
- Dubbo Mesh Solution, while supporting flexible Mesh deployment solutions such as Sidecar and Proxyless.
The overall architecture of Apache Dubbo can well meet the large-scale microservice practice of enterprises, because it is designed to solve the practical problems of ultra-large-scale microservice clusters from the beginning, whether it is Alibaba, ICBC, China Ping An, Ctrip and other community users, They have fully verified the stability and performance of Dubbo through years of large-scale production environment traffic. Therefore, Dubbo has unparalleled advantages in solving business landing and large-scale practice:
- out of the box
- High ease of use, such as the interface-oriented proxy feature of the Java version can realize local transparent calls
- Rich in functions, most of the microservice governance capabilities can be realized based on native libraries or lightweight extensions
- Designed for ultra-large-scale microservice clusters
- Extreme performance, high-performance RPC communication protocol design and implementation
- Horizontally scalable, easily supporting address discovery and traffic management of millions of cluster instances
- highly extensible
- Interception and extension of traffic and protocols during calling, such as Filter, Router, LB, etc.
- Extension of microservice governance components, such as Registry, Config Center, Metadata Center, etc.
- Enterprise-level microservice governance capabilities
- The de facto standard service framework supported by domestic public cloud vendors
- Years of enterprise practical experience test
Dubbo basic workflow

First of all, Dubbo is an RPC framework, which defines its own RPC communication protocol and programming method. As shown in the figure above, when using Dubbo, users first need to define the Dubbo service; secondly, after deploying the Dubbo service online, rely on Dubbo’s application layer communication protocol to realize data exchange, and the data transmitted by Dubbo must be serialized. And here the serialization protocol is fully extensible. The first step in using Dubbo is to define Dubbo services. The definition of services in Dubbo is a set of methods to complete business functions. You can choose to define them in a way that is bound to a certain language. For example, in Java, Dubbo services have a set of The Interface interface of the method can also use the language-neutral Protobuf Buffers IDL definition service. After the service is defined, the server (Provider) needs to provide a specific implementation of the service and declare it as a Dubbo service. From the perspective of the service consumer (Consumer), a service proxy can be obtained by calling the API provided by the Dubbo framework ( stub) object, and then you can call the service method like a local service. After the consumer initiates a call to the service method, the Dubbo framework is responsible for sending the request to the service provider deployed on the remote machine. After receiving the request, the provider will call the implementation class of the service, and then return the processing result to the consumer. This completes a complete service call. The data flow of Request and Response in the figure is shown.
It should be noted that in Dubbo, when we refer to services, we usually refer to RPC-grained interfaces or methods that provide the function of adding, deleting, and modifying a specific business, which is not the same as the services generally referred to in some microservice concept books concept.
In a distributed system, especially with the development of the microservice architecture, the deployment, release, and scaling of applications become extremely frequent. As an RPC consumer, how to dynamically discover the address of the service provider becomes a precondition for RPC communication . Dubbo provides an automatic address discovery mechanism to deal with the dynamic migration of machine instances in distributed scenarios. As shown in the figure below, the address of the provider and the consumer is coordinated by introducing the registration center. After the provider starts, it registers its own address with the registration center, and the consumer dynamically perceives the address list of the provider by pulling or subscribing to a specific node in the registration center. Variety.
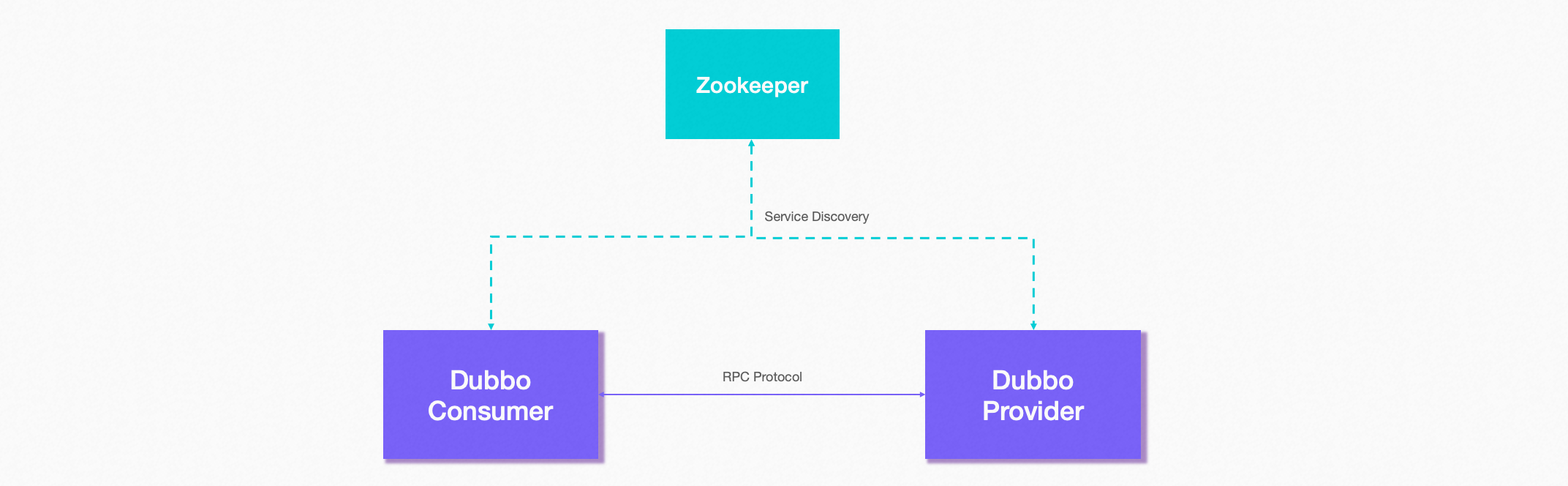
Dubbo core features
High performance RPC communication protocol
Service communication across processes or hosts is a basic capability of Dubbo. Dubbo RPC sends the request data (Request) to the backend service in a predefined protocol encoding method, and receives the calculation result (Response) returned by the server. RPC communication is completely transparent to the user, and the user does not need to care about how and where the request is sent, and only needs to get the correct call result for each call. In addition to the Request-Response communication model in synchronous mode, Dubbo3 also provides a richer selection of communication models:
- Consumer side asynchronous request (Client Side Asynchronous Request-Response)
- Provider side asynchronous execution (Server Side Asynchronous Request-Response)
- Consumer request stream (Request Streaming)
- Provider response stream (Response Streaming)
- Bidirectional Streaming
For details, please refer to the list of optional protocols implemented by each language SDK or Triple Protocol
Automatic service (address) discovery
Dubbo’s service discovery mechanism allows microservice components to evolve independently and be deployed arbitrarily, and the consumer can complete communication without knowing the deployment location and IP address of the peer. Dubbo provides a Client-Based service discovery mechanism, and users can enable service discovery in various ways:
- Use independent registry components, such as Nacos, Zookeeper, Consul, Etcd, etc.
- Leave the organization and registration of services to the underlying container platform, such as Kubernetes, which is understood to be a more cloud-native usage
Run state traffic control
Transparent address discovery allows Dubbo requests to be sent to any IP instance, and traffic is randomly allocated during this process. When richer and finer-grained control of traffic is required, Dubbo’s traffic control strategy can be used. Dubbo provides strategies including load balancing, traffic routing, request timeout, traffic degradation, retry, etc., based on these basic capabilities You can easily implement more scenario-based routing solutions, including canary release, A/B testing, weight routing, same-region priority, etc. What’s even cooler is that Dubbo supports traffic control policies to take effect dynamically in the running state without redeployment . For details, please refer to:
Rich extension components and ecology
Dubbo’s powerful service governance capabilities are not only reflected in the core framework, but also include its excellent expansion capabilities and the support of surrounding supporting facilities. Through the definition of extension points that exist in almost every key process, such as Filter, Router, and Protocol, we can enrich Dubbo’s functions or realize the connection with other microservice supporting systems, including Transaction and Tracing. Currently, there are implementations that extend through SPI For details, please refer to the details of Dubbo extensibility, and you can also find more extension implementations in the apache/dubbo-spi-extensions project. For details, please refer to:
Cloud Native Design
Dubbo is designed to fully follow the development concept of cloud-native microservices, which is reflected in many aspects. First, it supports cloud-native infrastructure and deployment architecture, including containers, Kubernetes, etc. The overall solution of Dubbo Mesh is also in version 3.1 Official release; on the other hand, many core components of Dubbo have been upgraded for cloud native, including Triple protocol, unified routing rules, and support for multiple languages.
It is worth mentioning that how to use Dubbo to support elastic scaling services such as Serverless is also planned in the future, including using Native Image to improve Dubbo’s startup speed and resource consumption.
Combined with the current version, this section mainly expands Dubbo’s cloud-native features from the following two points
Kubernetes
For Dubbo microservices to support Kubernetes platform scheduling, the most basic thing is to realize the alignment of the dubbo service life cycle and the container life cycle, which includes life cycle events such as Dubbo startup, destruction, and service registration. Compared with the past where Dubbo defined life cycle events by itself and required developers to abide by the agreement during operation and maintenance practice, the underlying infrastructure of Kubernetes defines strict component life cycle events (probes), and instead requires Dubbo to adapt according to the agreement.
Kubernetes Service is another level of adaptation, which reflects the trend of service definition and registration sinking to the cloud-native underlying infrastructure. In this mode, users no longer need to build additional registry components, Dubbo consumer end nodes can automatically connect to Kubernetes (API-Server or DNS), and query the instance list (Kubernetes endpoints) according to the service name (Kubernetes Service Name) . At this point, the service is defined through the standard Kubernetes Service API and dispatched to each node.
Dubbo Mesh
Service Mesh has been widely disseminated and recognized in the industry, and is considered to be the next-generation microservice architecture, mainly because it solves many difficult problems, including transparent upgrades, multilingualism, dependency conflicts, and traffic management. The typical architecture of Service Mesh is to intercept all egress and ingress traffic by deploying independent Sidecar components, and integrate rich traffic management strategies such as load balancing and routing in Sidecar. In addition, Service Mesh also requires a control plane (Control Panel) to realize the control of Sidecar traffic, that is, to issue various policies. We call this architecture here Classic Mesh.
However, no technical architecture is perfect, and classic Mesh also faces the problem of high cost at the implementation level
- Operation and maintenance control panel (Control Panel) is required
- Need to operate and maintain Sidecar
- Need to consider how to migrate from the original SDK to Sidecar
- It is necessary to consider the performance loss of the entire link after introducing Sidecar
In order to solve the related cost problems introduced by Sidecar, Dubbo introduced and implemented a new Proxyless Mesh architecture. As the name suggests, Proxyless Mesh refers to the deployment without Sidecar, and the Dubbo SDK directly interacts with the control plane. The architecture diagram is as follows
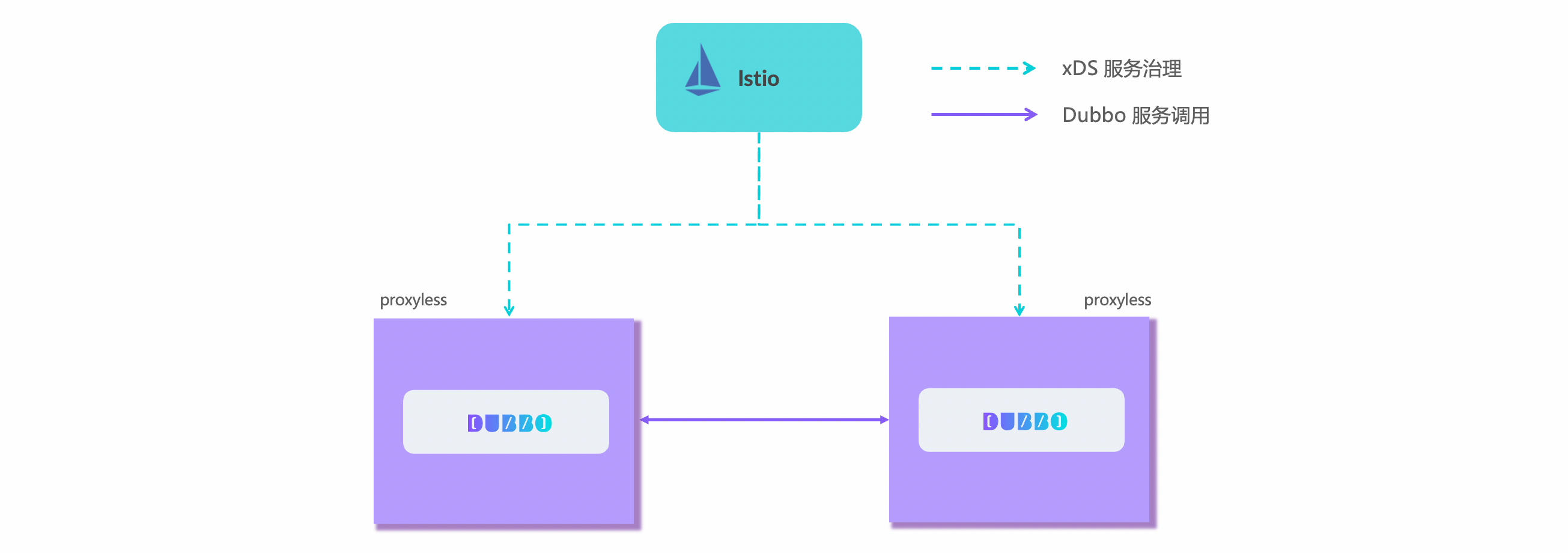
It can be imagined that in different organizations and different development stages, microservices built with Dubbo will allow three deployment architectures in the future: traditional SDK, Sidecar-based Service Mesh, and Proxyless Mesh without Sidecar. Based on Sidecar’s Service Mesh, that is, the classic Mesh architecture, the independent sidecar runtime takes over all the traffic, separate from the Sidecar’s Proxyless Mesh, and the secondary SDK directly communicates with the control plane through xDS. Dubbo microservices allow deployment on physical machines, containers, and Kubernetes platforms, and can use Admin as the control plane and manage them with unified traffic governance rules.